Diseño de API Serverless para la trazabilidad agrícola: de la tierra 🌱 a la taza de café ☕
Normalmente, escribo artículos técnicos sobre los fundamentos de las arquitecturas y servicios cloud; sin embargo, después de algunas charlas y buenos cafés con Samuel (connexus) me doy a la tarea de escribir una serie de artículos con una aplicación práctica de todas las cosas que normalmente hablo en otros blogs.
El caso de uso: fundamentalmente es una búsqueda de un uso con sentido de este desbordamiento de datos e información en el que vivimos. Samuel me transmitió su intención de tener la posibilidad de contar una historia, un camino, desde el momento que se siembra una planta de café hasta el momento que se coloca en la taza de un cliente o que se vende una bolsa de café tostado.
Con esto en mente y mi ya conocida afición por las aplicaciones serverless me di a la tarea de diseñar un mínimo producto viable (MVP) con una API que permita trazar este camino utilizando AWS Lambda y DynamoDB.
Lo primero es entender cuáles son las etapas que se quieren registrar en el proceso: Siembra, cosecha, despulpado, fermentación, secado, trillado, empaque, traslado, tostado y venta.
Dejo por aquí un artículo de connexus donde cuenta en detalle las etapas del proceso. Acompañamos el camino del café
El ciclo de vida del proceso agrícola es estacionario por naturaleza. Con esto en mente, claramente pensé en un sistema serverless como primera opción, con AWS Lambda como sistema de cómputo y DynamoDB como almacenamiento de datos.
La planta como eje principal del diseño
La planta será el elemento principal del diseño de la estructura de datos. Cuando empezamos a trabajar con los datos reales de Connexus, nos encontramos con algo que cambió el enfoque del proyecto: 17,301 plantas de café geolocalizadas con coordenadas GPS reales, extraídas de archivos KML/KMZ generados por levantamientos topográficos profesionales.
Cada planta tiene su posición exacta en el terreno, con latitud, longitud y altitud. Los datos provienen de variedades como Caturra, Chiroso y Geisha, cada una mapeada individualmente en la finca Santa Sofía, ubicada en Colombia.
{
"plantId": "86066",
"latitude": X.942530693412659,
"longitude": -Y.28797111615484,
"altitude": 0.0,
"variety": "GEISHA",
"status": "active",
"orden": 1,
"name": "1",
"fid": 6066,
"origFid": 10000,
"createdAt": "2026-02-21T00:00:45.911695"
}
Este descubrimiento nos llevó a priorizar: antes de implementar las etapas de procesamiento del café, necesitábamos tener un sistema sólido para gestionar y consultar las plantas. Sin plantas bien registradas, no hay trazabilidad posible.
De Single Table Design a dos tablas con propósito
En el diseño original pensé en un Single Table Design ambicioso con entidades como Farm, Plot, Plant, Harvest Batch y Bag, todas en una sola tabla con claves compuestas. Sigo creyendo que es el camino correcto para la trazabilidad completa, y más de una vez he dejado por aquí o he contado en alguna de mis charlas lo que el artículo de Alex DeBrie sobre Single Table Design me ha enseñado.
Sin embargo, al enfrentarnos con los datos reales, la implementación tomó un camino más pragmático. Creamos dos tablas en DynamoDB:
Plants Table
La tabla principal del sistema. Almacena las 17,301 plantas con sus coordenadas GPS y metadatos. Tiene tres índices secundarios globales (GSI) que responden a los patrones de acceso reales que necesitamos:
resource "aws_dynamodb_table" "plants" {
name = "${local.name_prefix}-plants"
billing_mode = "PAY_PER_REQUEST"
hash_key = "plantId"
global_secondary_index {
name = "StatusIndex"
hash_key = "status"
projection_type = "ALL"
}
global_secondary_index {
name = "VarietyIndex"
hash_key = "variety"
projection_type = "ALL"
}
global_secondary_index {
name = "VarietyOrdenIndex"
hash_key = "variety"
range_key = "orden"
projection_type = "ALL"
}
}
El VarietyOrdenIndex es particularmente útil: permite consultar todas las plantas de una variedad específica ordenadas por su número de orden en el terreno, que es exactamente lo que necesitamos para la visualización en mapa.
Orders Table
Preparada para el futuro marketplace que conectará productores con consumidores directamente. Por ahora está lista, pero pendiente de implementación completa.
resource "aws_dynamodb_table" "coffee_orders" {
name = "${local.name_prefix}-orders"
billing_mode = "PAY_PER_REQUEST"
hash_key = "orderId"
range_key = "timestamp"
global_secondary_index {
name = "UserIdIndex"
hash_key = "userId"
range_key = "timestamp"
projection_type = "ALL"
}
}
La arquitectura que construimos
La arquitectura final es serverless de punta a punta, desplegada con Terraform y servida a través de AWS Amplify en el frontend:
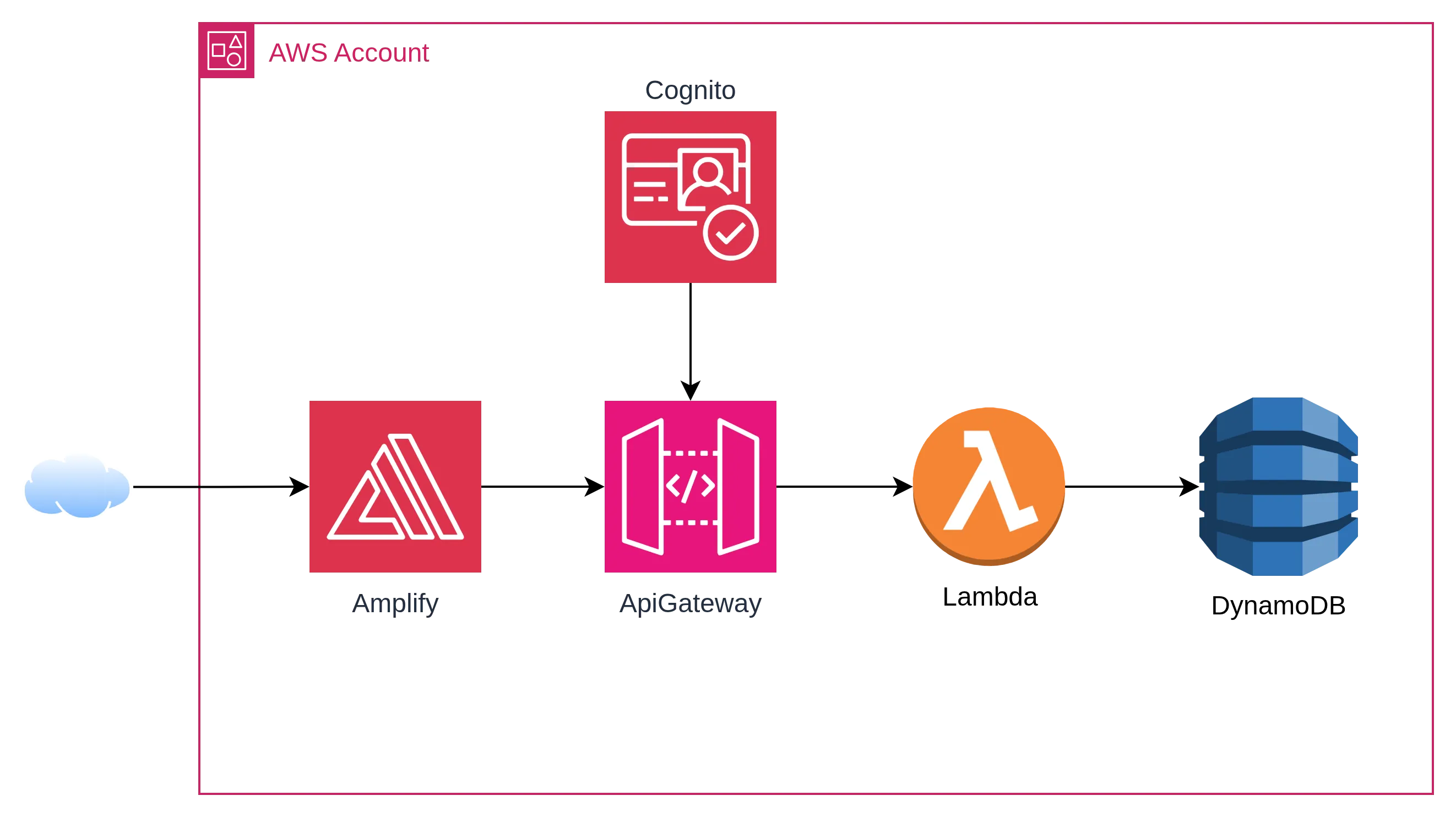
Los servicios:
- AWS Amplify como hosting del frontend web (Astro + Tailwind)
- API Gateway HTTP con CORS habilitado
- Cognito User Pool con autenticación JWT — todos los endpoints pasan por autenticación, las APIs son accesibles únicamente desde la aplicación
- Una sola Lambda en Node.js 20 que maneja todos los endpoints
- DynamoDB con dos tablas en modo on-demand
La decisión de usar una sola Lambda fue deliberada: simplifica el despliegue, reduce el overhead de infraestructura y es fácil de migrar a microservicios después si el volumen lo requiere.
Los endpoints
En lugar de los ~20 endpoints del diseño original, implementamos 5 que cubren las necesidades reales del MVP. Todos los endpoints requieren autenticación JWT de Cognito y son accesibles desde la aplicación web:
# Lectura
GET /plants → Lista plantas con paginación y filtro por variedad
GET /plants/{plantId} → Detalle de una planta
GET /orders → Listar órdenes del usuario
# Escritura
PUT /plants/{plantId} → Actualizar planta
POST /orders → Crear orden
El endpoint GET /plants soporta paginación y filtro por variedad usando el GSI VarietyOrdenIndex. Actualmente las variedades registradas en el sistema son:
| Variedad | Plantas | Fuente GPS |
|---|---|---|
| Caturro | 5,158 | CATURRO_PUNTOS_COD.kmz |
| Chiroso | 6,068 | CHIROSO_PUNTOS_COD.kmz |
| Sin asignar | 6,073 | LAYERS.kmz (pendiente clasificación) |
| Total | 17,301 |
El proceso de carga de datos reales
Una parte importante del proyecto que no estaba en el diseño original fue el proceso de ETL para cargar las plantas reales. Los datos venían de archivos KML/KMZ generados por levantamientos topográficos con GPS y tuvimos que construir scripts en Python para:
- Extraer las coordenadas de los archivos KML/KMZ
- Transformar los datos al formato de DynamoDB, asignando variedades y orden
- Cargar las 17,301 plantas a la tabla
# Extraer datos del KMZ
python3 extract_plants.py
# Subir a DynamoDB
python3 upload_to_dynamodb.py
Este proceso nos enseñó que en proyectos reales, la preparación de datos consume tanto o más tiempo que la infraestructura.
Despliegue
Como en otros posts, toda la infraestructura se gestiona con Terraform como herramienta de IaC (Infrastructure as Code). Esto nos permite versionar la infraestructura junto con el código, reproducir el entorno de manera consistente y mantener un estado remoto en S3 para trabajar en equipo.
El backend de la API, las tablas de DynamoDB, Cognito, API Gateway y la Lambda se definen en archivos .tf y se despliegan con los comandos habituales de Terraform. El frontend en Astro se despliega automáticamente a través de AWS Amplify conectado al repositorio.
Volumetría real vs estimada
En el diseño original estimé 16,168 registros nuevos por año basándome en supuestos teóricos. La realidad es que solo con las plantas ya tenemos 17,301 registros, y eso sin contar las etapas de procesamiento que vendrán después.
La buena noticia: DynamoDB en modo PAY_PER_REQUEST maneja esto sin problema y el costo es mínimo para este volumen. La decisión de no usar Single Table Design por ahora también simplifica las consultas y el mantenimiento.
Lo que viene
El diseño original con Single Table Design, las etapas de procesamiento del café (cosecha, despulpado, fermentación, secado, trillado, empaque) y la trazabilidad completa de planta a taza siguen siendo el objetivo. Ahora que tenemos las plantas geolocalizadas y la infraestructura base funcionando, los siguientes pasos son:
- Implementar el registro de etapas de procesamiento por lote de cosecha
- Conectar las plantas con los lotes y los sacos
- Construir la trazabilidad completa: dado un saco de café, poder llegar hasta las plantas que contribuyeron
- Activar el marketplace con la tabla de órdenes
En algún próximo post contaré un poco más del proceso de construcción de estas siguientes fases y cómo evoluciona la arquitectura.
Gracias por leer,
Saludos!